聚类分析过程
一般聚类分析的数据源是需要相对干净的,即需要做统一的特征清洗、特征变换过程,即空值、非法值、异常值、类别变量等的处理。主要过程如下:
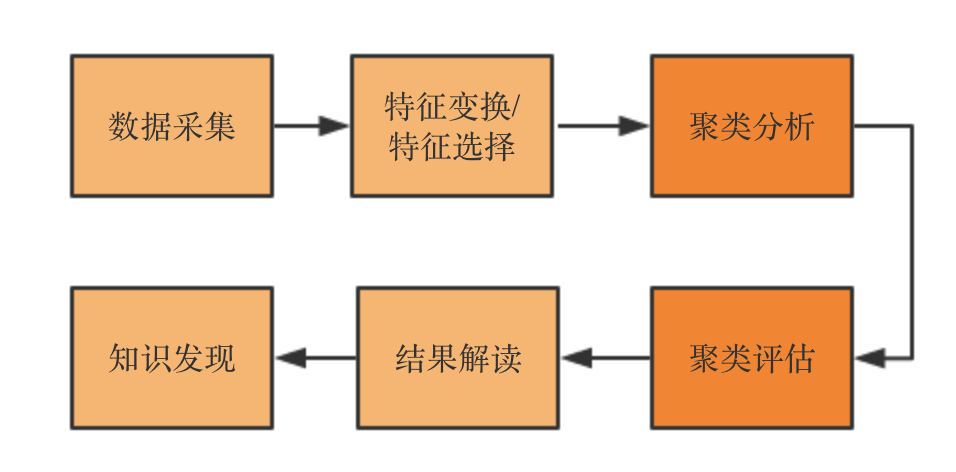
数据采集:我们可以认为是统一的ETL过程,这里涉及埋点、转发、存储、提取等过程。是典型的数据分析前置过程。
特征变换/特征选择:聚类对异常数据特别敏感,同时原始数据直接进入聚类分析不大现实。特征处理包含行维度、列维度的处理,行维度主要包括:空值、非法值、异常值等方面的处理,而列维度涉及降维处理,冗余的列对聚类影响较大,所以一般聚类分析之前会做一次PCA。
聚类分析、聚类评估:下文将重点举例描述
结果解读:无监督学习,一般没有label,聚类的数量也是未知的,需要结合业务知识进一步解读聚类结果,比如从用户画像维度进一步切分同个分类的数据,从统计维度挖掘特征。
知识发现:解读结果之后,需要落地实现或者输出报告,我们把这个过程称为知识发现的过程。聚类结果产生的label结果,往往可以作为监督学习的来源。
下面举两个经典的聚类分析算法进一步说明。
Kmeans
基于距离聚类的聚类算法
算法步骤:
1、根据设定分类数量,随机生成N个中心点
2、每个点计算与中心点距离,按最近距离合并分类
3、基于2重新计算每个分类的中心点
4、重复2~3,直到中心点收敛
sklearn实现
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
pred = kmeans.fit_predict(X)聚类效果
GMM
高斯混合模型是几个高斯分布的叠加,每一个分布代表一个分类
算法步骤:
1、设定分类数量
2、对每一个高斯分布均值、方差随机初始化
3、计算每个样本的在各个高斯分布的概率、权重值,Expectation-step
4、根据最大似然重新估算高斯分布均值、方差,Maximization-step
5、重复3~4直到高斯分布均值和方差收敛
sklearn实现
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3)
gmm = gmm.fit(X)
pred_gmm = gmm.predict(X)聚类效果
模型评价
GMM和KMeans分类结果有一定的随机性,可能得到局部优化解,需要多次微调。
GMM是概率分类结果,可以对比topN分类,比如文档聚类;GMM计算代价更大,大数据集是个负担。
评估指标
聚类算法的评估主要衡量两个方面:同类紧密程度、类间分散程度;从不同指标看,同类越紧密、类间越分散,聚类效果越好
基本上为无监督聚类,所以“Rand Index”之类的指标不是太实用,常用EIBOW方法 ,根据SSE评估聚类效果,另外对于聚类结果评估可以采用以下两种方式:
1、Silhouette index
s = (b-a)/max(a,b)
ai:同分类内,单点与其他点的平均距离
bi:分类中的点与最近分类点的平均距离
a:所有点ai的均值
b:所有点bi的均值基于轮廓的衡量方法,可能不适合 Single link、Complete link、DBSCANE等聚类方法。
2、Calinski-Harabasz
CH指标通过“同类”、“类间”协方差矩阵的迹(各个变量的方差)衡量,计算速度较快。